Performance
When it comes to performance, FhGFS benefits from an early stage design decision to focus solely on HPC applications. Continuous internal benchmarks as well as participation in public test settings make sure there is no deviation from this path. With an extremely wide variety of test metrics it is difficult to identify the important ones. A survey of the DICE program, asking HPC data center representatives about the most important metrics for performance aspects, gives much needed input in this area. Of the respondents, 77.8 percent ranked bandwidth number one, followed by metadata operations. Hence, these are the metrics on which the FhGFS team is focused.Benchmarks in Figures Three and Four were performed using FhGFS 2012.10-beta1 on the Fraunhofer Seislab cluster (20 Servers for Storage and Metadata (2x Intel Xeon X5660 @ 2.8 GHz, 48 GB RAM, 4x Intel 510 Series SSD (RAID 0), Ext4, QDR Infiniband, Scientific Linux 6.3; Kernel 2.6.32-279). Single node performance on the local file system without FhGFS in the Seislab cluster is 1,332 MB/s (write) and 1,317 MB/s (read), i.e. the theoretical maximum for 20 servers would be 26,640 MB/s (write) and 26,340 MB/s (read). The sequential read/write on up to 20 servers with 160 client processes shows, that FhGFS achieves a sustained performance of 94.7% for writes and 94.1% for reads.
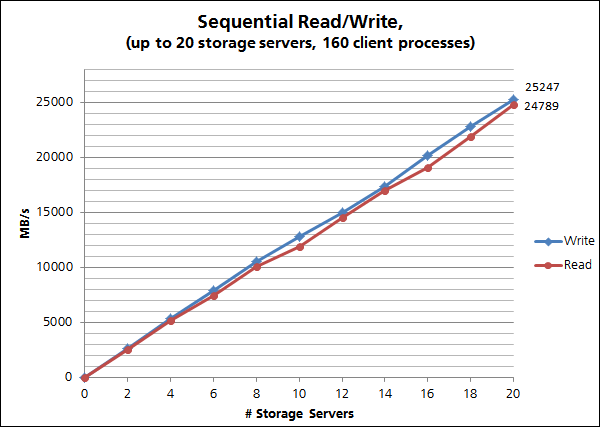
Figure Three: FhGFS sequential read/write performance
For the metadata operations benchmark, up to 20 servers and up to 160 client processes were used. The results illustrate that more than 500,000 files could be created per second, i.e. creation of 1 billion files would take about half an hour.
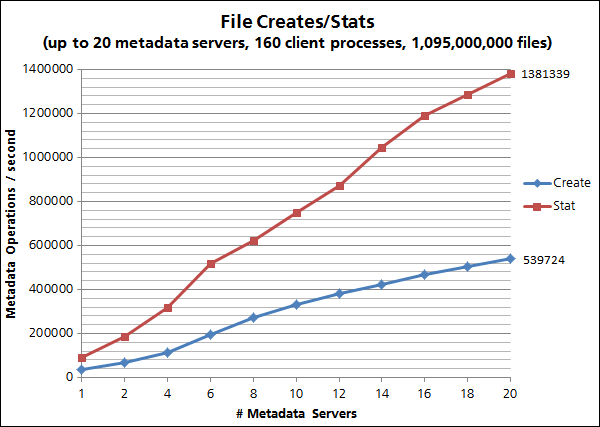
Figure Four: FhGFS metadata file creation performance
Besides the internal benchmarks, participation in public test settings have shown both the ability of FhGFS to saturate network connections and demonstrate other advantages over various parallel file systems available to the HPC community. One such test setting is the "100GBit Testbed" between the German Technical Universities of Freiberg and Dresden in 2011. The physical distance between their data centers is about 37 miles (60km) and a 100GBit connection was established between them. In a second step, the length of the connecting fabric was increased to 250 miles (400km), allowing long distance test runs. Figure Five shows an overview of the hardware settings with the data centers at each university, HP storage servers, a DDN storage system and the 100GBit network interconnect between them.
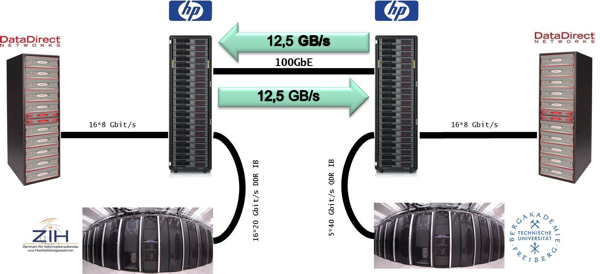
Figure Five: FhGFS configuration over the "100GBit Testbed" between two sites. © 2013 Michael Kluge, TU Dresden
in addition to other tests (video, etc), performance of several parallel file systems was tested in this setting. GPFS, Lustre and FhGFS took part in this test, each with full tuning-support from the respective supplier. [Note: the following reflects a clarification from the original article.] FhGFS showed excellent performance values, both for bi-directional and uni-directional streaming throughput and was fastest on the 250 miles track. Table 1 shows the results of the tests for FhGFS in percentages of the theoretical peak performance. Further information to the 100GBit Testbed can be found from the TU Dresden.
| File System | Uni-Directional | Bi-Directional |
|---|---|---|
| FhGFS | 99.2% @ 250 miles | 89,6% @ 250 miles |
Table 1: 100GBit Testbed Results. Theoretical peak: 12.5GB/s uni-, 25GB/s bi-directional
FhGFS On-demand: A Use Case
Fraunhofer Seislab was designed to take advantage of 2 storage tiers: 100 TB main storage on SATA-HDDs and 1TB local storage per node on SSDs. For each cluster job submitted to the batch system, in this case the Torque Resource Manager, a dedicated on-demand FhGFS is created from the local node storage (those nodes belonging to the submitted job). Calculations on temporary data can use this fast and "local" FhGFS and only final results need to go to the slower main storage.This approach yields significant performance gains. To prove this concept, a Fraunhofer implementation of mergesort for large seismic datasets that do not fit into memory was slightly adjusted to make use of the fast local filesystem. The algorithm is mostly I/O bound. Instead of writing intermediate results to the main storage, they were written into the local FhGFS and the speed of the mergesort for a 5TB sized file improved by up by a factor of two.

