Crafted in Germany, FhGFS is ready to take on the worlds biggest IO challenges
![]() The Fraunhofer Parallel File System (FhGFS) is the high-performance parallel file system of the Fraunhofer Institute for Industrial Mathematics in Kaiserslautern, Germany. It includes a distributed metadata architecture that has been designed to provide the scalability and flexibility required to run today's most demanding HPC applications while being easy to use and manage.
The Fraunhofer Parallel File System (FhGFS) is the high-performance parallel file system of the Fraunhofer Institute for Industrial Mathematics in Kaiserslautern, Germany. It includes a distributed metadata architecture that has been designed to provide the scalability and flexibility required to run today's most demanding HPC applications while being easy to use and manage.
"There must be a better way to do this!" is the simple motive that became the driving force for the development of a new parallel file system by researchers at the Fraunhofer Institute for Industrial Mathematics (ITWM) in Kaiserslautern Germany. After a fruitless search for an easy to use, low cost, highly scalable alternative to the File System on the institute's supercomputer, a team of people working with Dr. Franz-Josef Pfreundt, head of ITWM's Competence Center High-Performance Computing (CC-HPC), decided in 2004 to fill this gap and develop their own parallel file system. That's when the Fraunhofer Parallel File System (FhGFS) was born.
| About Fraunhofer |
|
Fraunhofer (FhG) is one of Europe's largest research companies. Its
mission is to undertake applied research of direct utility to private and
public enterprise and of wide benefit to society. Fraunhofer maintains
more than 80 research institutions worldwide -- among them 60 institutes in
Germany -- and employs over 20,000 people, the majority with masters and
doctorate degrees in natural sciences. More than 80 percent of the annual
research budget of 2 billion Euro (~$2.6 billion, 2012) stem from contract
research, the rest from public funding.
The ITWM is one of Fraunhofer's institutes and the first to focus research on industrial mathematics, working on fields such as optimization, fluid dynamics and simulations as well as HPC. The CC-HPC at the ITWM is active in several fields, developing HPC tools such as FhGFS or GPI but also proprietary HPC applications for customers. The department also has a strong focus on CPU based visualization techniques and Green-by-IT technologies. |
Starting as a high-performance parallel file system, dedicated to the HPC community, it is used today in HPC centers of universities, research centers and industry worldwide; among them TOP 500 clusters like the one at the Goethe University in Frankfurt, Germany.
Taking advantage of a "clean sheet of paper design", the developer team, lead by Sven Breuner, was able to set the requirements and key features of the FhGFS without any constraints. The goal was a system with a scalable multi-threaded architecture that distributes metadata and doesn't require any kernel patches, supports several network interconnects including native InfiniBand and is easy to install and manage. All these considerations lead to three cornerstones for FhGFS development:
- Maximum Scalability
- Maximum Flexibility
- Easy to Use
Key Concepts
FhGFS runs on any Linux machine and consists of several components that include services for clients, metadata servers and storage servers. In addition, there is a service for the management host as well as one for a graphical administration and monitoring system. A diagram depicting the architecture is given in Figure One.To run FhGFS, at least one instance of the metadata server and the storage server is required. But FhGFS allows multiple instances of each service to distribute the load from a large number of clients. To guarantee maximum scalability for the file system, each individual component was designed to scale. Consequently, the system itself scales with the number of clients, metadata servers and storage servers, regardless of their combination.
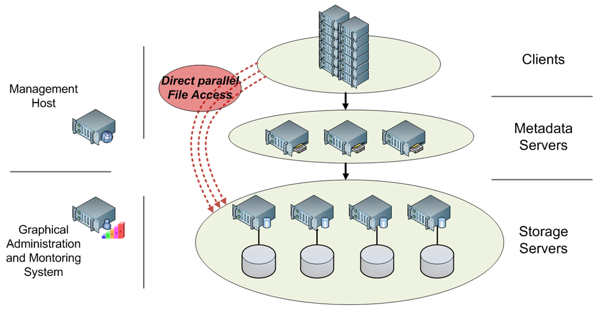
Figure One: FhGFS component design
Many thoughtful implementation ideas contribute to the ability of FhGFS to scale. Naturally, file contents are distributed over several storage servers using striping, i.e. each file is split into chunks of a given size and these chunks are distributed over the existing storage servers. The size of these chunks can be defined by the file system administrator. In addition, also the metadata is distributed over several metadata servers on a directory level, with each server storing a part of the complete file system tree. This approach allows much faster access on the data. Other factors include direct and parallel access to files on the storage servers by the clients as well as support for high-speed network interconnects such as native InfiniBand.
Flexibility can take various forms with FhGFS. Additional clients as well as metadata or storage servers can easily be added into an existing system without any downtime. In addition, the servers run on top of an existing local file system. While there are no restrictions to the type of underlying file system, recommendations are to use ext4 for the metadata servers and XFS for the storage servers. In terms of hardware there is no strict requirement for dedicated hardware for individual services. This design allows a file system administrator to start the services in any combination on a given set machines and expand in the future. A pretty common way to take advantage of this is combining metadata servers and storage servers on the same machines as shown in Figure Two.
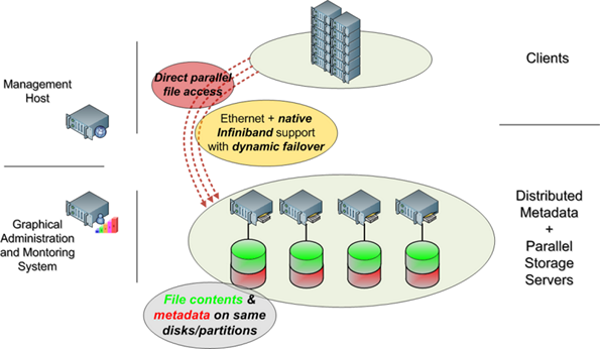
Figure Two: FhGFS with combined metadata and storage servers on the same machine
One of the newest features that strengthen flexibility is support for an on-demand parallel file system instance. A single command line creates an instance of FhGFS over a set of nodes. This feature offers a variety of new use cases, e.g. the possibility to set up a dedicated file system for an individual cluster job or for cloud computing. It also speeds up file system tests, because it is a fast and easy way to setup such a testing system.
On top of this, support for various network-interconnects with dynamic failover as well as many different Linux distributions and kernels allow flexible use in almost every environment. All these options together enable a file system administrator to fine tune his very own installation of FhGFS in a variety of ways. FhGFS comes with a rich set of utilities and the developers have put together insider tips on how to tune the file system to the given hardware setting. These tips can be found together with installation instructions and further information in the publicly available FhGFS wiki.
FhGFS server processes run in userspace and the client itself is a lightweight kernel module that doesn't require any kernel patches. FhGFS runs on any Linux distribution and does not impose hardware requirements on the user. (Of course, faster hardware helps increase system thoughput.)
On strength of FhGFS is ease of use. The file system has a very simple setup and startup mechanism. For users that prefer a graphical interface over command lines, a Java based GUI is available. The GUI provides monitoring of the FhGFS state and management of system settings in an intuitive way with no need for command line interaction. Besides managing and administrating the FhGFS installation, this tool also offers a couple of monitoring options to immediately identify performance problems within the system.
Performance
When it comes to performance, FhGFS benefits from an early stage design decision to focus solely on HPC applications. Continuous internal benchmarks as well as participation in public test settings make sure there is no deviation from this path. With an extremely wide variety of test metrics it is difficult to identify the important ones. A survey of the DICE program, asking HPC data center representatives about the most important metrics for performance aspects, gives much needed input in this area. Of the respondents, 77.8 percent ranked bandwidth number one, followed by metadata operations. Hence, these are the metrics on which the FhGFS team is focused.Benchmarks in Figures Three and Four were performed using FhGFS 2012.10-beta1 on the Fraunhofer Seislab cluster (20 Servers for Storage and Metadata (2x Intel Xeon X5660 @ 2.8 GHz, 48 GB RAM, 4x Intel 510 Series SSD (RAID 0), Ext4, QDR Infiniband, Scientific Linux 6.3; Kernel 2.6.32-279). Single node performance on the local file system without FhGFS in the Seislab cluster is 1,332 MB/s (write) and 1,317 MB/s (read), i.e. the theoretical maximum for 20 servers would be 26,640 MB/s (write) and 26,340 MB/s (read). The sequential read/write on up to 20 servers with 160 client processes shows, that FhGFS achieves a sustained performance of 94.7% for writes and 94.1% for reads.
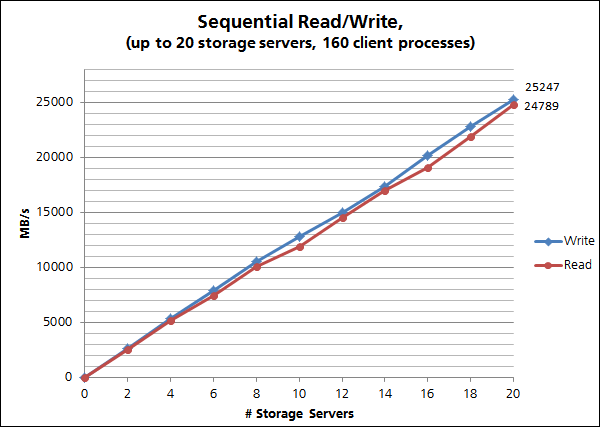
Figure Three: FhGFS sequential read/write performance
For the metadata operations benchmark, up to 20 servers and up to 160 client processes were used. The results illustrate that more than 500,000 files could be created per second, i.e. creation of 1 billion files would take about half an hour.
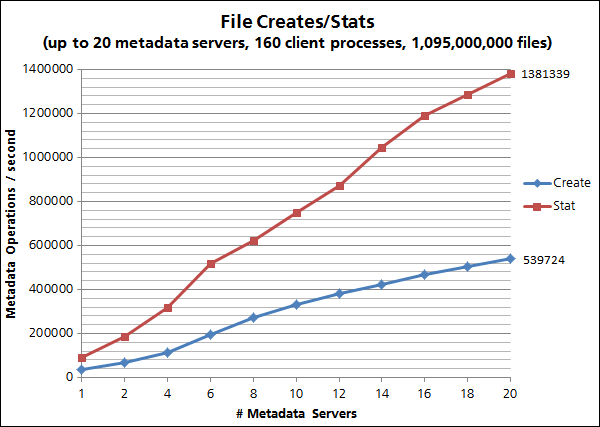
Figure Four: FhGFS metadata file creation performance
Besides the internal benchmarks, participation in public test settings have shown both the ability of FhGFS to saturate network connections and demonstrate other advantages over various parallel file systems available to the HPC community. One such test setting is the "100GBit Testbed" between the German Technical Universities of Freiberg and Dresden in 2011. The physical distance between their data centers is about 37 miles (60km) and a 100GBit connection was established between them. In a second step, the length of the connecting fabric was increased to 250 miles (400km), allowing long distance test runs. Figure Five shows an overview of the hardware settings with the data centers at each university, HP storage servers, a DDN storage system and the 100GBit network interconnect between them.
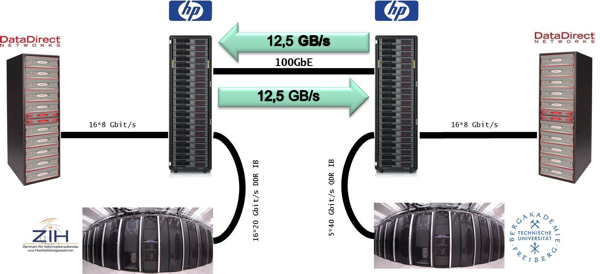
Figure Five: FhGFS configuration over the "100GBit Testbed" between two sites. © 2013 Michael Kluge, TU Dresden
in addition to other tests (video, etc), performance of several parallel file systems was tested in this setting. GPFS, Lustre and FhGFS took part in this test, each with full tuning-support from the respective supplier. [Note: the following reflects a clarification from the original article.] FhGFS showed excellent performance values, both for bi-directional and uni-directional streaming throughput and was fastest on the 250 miles track. Table 1 shows the results of the tests for FhGFS in percentages of the theoretical peak performance. Further information to the 100GBit Testbed can be found from the TU Dresden.
| File System | Uni-Directional | Bi-Directional |
|---|---|---|
| FhGFS | 99.2% @ 250 miles | 89,6% @ 250 miles |
Table 1: 100GBit Testbed Results. Theoretical peak: 12.5GB/s uni-, 25GB/s bi-directional
FhGFS On-demand: A Use Case
Fraunhofer Seislab was designed to take advantage of 2 storage tiers: 100 TB main storage on SATA-HDDs and 1TB local storage per node on SSDs. For each cluster job submitted to the batch system, in this case the Torque Resource Manager, a dedicated on-demand FhGFS is created from the local node storage (those nodes belonging to the submitted job). Calculations on temporary data can use this fast and "local" FhGFS and only final results need to go to the slower main storage.
This approach yields significant performance gains. To prove this concept, a Fraunhofer implementation of mergesort for large seismic datasets that do not fit into memory was slightly adjusted to make use of the fast local filesystem. The algorithm is mostly I/O bound. Instead of writing intermediate results to the main storage, they were written into the local FhGFS and the speed of the mergesort for a 5TB sized file improved by up by a factor of two.
FhGFS and Exascale
By providing leading edge technology and solutions for the HPC community, Fraunhofer is also important part of the exascale discussion occurring at conferences and the HPC community in general. Developers of the CC-HPC form a creative think tank to address this topic, identify the challenges and, most important, find smart and new solutions, to deal with the challenges and pave the way to exascale computing. Having a vast expertise in HPC tools and applications at the same time, Fraunhofer has experience that can be used to attack the exascale problem from several directions, the parallel file system being one of them.Looking at the first supercomputer to achieve 10 PFlops, the Japanese K Computer, and its dimensions (864 cabinets, 88,000 nodes) as well as energy consumption (12.6 MWatt), it's rather safe to say that an exascale machine would probably not simply consist of 100 such machines. At the same time, it is certain, that an exascale system will consume more power and consist of more compute cores. Hence, power consumption, fault tolerance as well as (software) scalability are the challenges to be solved, in order to achieve a usable exascale system. A parallel file system can contribute to that in various ways.
One example on how to address the power consumption on the file system level is to leverage the natural levels of storage: current jobs, short-term working set and long-term data archive. By introducing support for hierarchical storage management (HSM) and using energy efficient technologies, such as tapes, for long-term storage, a significant reduction in energy consumption can be achieved. For this purpose, Fraunhofer ITWM has teamed up with Germany based Grau Data. FhGFS will implement HSM support into its metadata server that will then directly interact with the Grau Archive Manager to provide a scalable HSM solution.
On the scalability side, static striping patterns, as they are common today, are one of the bottlenecks for throughput scaling. Balancing the number of storage targets is almost impossible, as in most cases it is not known, how large files in the file system will be. Optimizing for small files, i.e. using few storage targets, slows down performance for large files, while optimizing for larger files using many storage targets increases the overhead and potentially slows down small file performance. Technically, a user could influence these patterns, but a regular file system user shouldn't have to deal with the number of storage targets. As a solution, FhGFS is going to provide automated irregular striping, allocating more targets as the file grows. The beauty of this solution is that additional targets are only used, when the performance gain outnumbers the additional overhead. This ensures fast access to any file, regardless of its size.
Assuming an exascale system will have by far more components than today's systems, failures of parts will become more frequent. Fault tolerance, especially keeping data available when something in the system breaks, becomes a more and more important requirement for parallel file systems. Using redundant arrays of storage doesn't quite solve the problem. Besides being expensive and complex to configure/manage, eventually it just lowers the possibility of data loss by hoping the redundant array doesn't break. Keeping the data redundant within the file system is a better solution and the design path chosen by the FhGFS team. This method keeps complexity low and only adds cost for inexpensive additional disk capacity. Current versions already come with High Availability (HA) support and allow mirroring metadata and/or file contents on a per-file/per-directory base as well as individual mirrors for each file/directory.
Finally, what happens if and I/O bound job still doesn't run as fast as expected? In order to address this issue, FhGFS provides good monitoring and analysis tools that provide live statistics, profiling and much more. FhGFS already comes with a graphical monitoring and administration solution -- the AdMon. The challenge to all such tools is in how to visualize all this information in a way that is still intuitive for users and administrators.
Where to get FhGFS?
FhGFS is provided free of charge and the packages of the current stable release (2012.10-r4) can be downloaded directly from the project website at www.fhgfs.com or from repositories for the different Linux distributions. Commercial support is available directly from Fraunhofer or from its international partners. New FhGFS updates will also be announced on the FhGFS Twitter page.
Tobias Goetz holds an M.S. in Computer Science from University of Tübingen, Germany and has been a researcher and project manager at the Competence Center High-Performance Computing at the Fraunhofer Institute for Industrial Mathematics in Kaiserslautern, Germany since 12/2008.