Does the speed of light limits how big a cluster we can build
Recently, I started to think about the physical limits and how these limits would effect the size of clusters. I did some back of the envelope math to get an estimate of how c (the speed of light) can limit cluster size. As clusters continue to grow in size and the push toward exascale performance, the following analysis may become more important in designing HPC systems. I want to preface this discussion, however, with a disclaimer that I thought about this for all of 20 minutes. I welcome variations or refinements on my ciphering.
Update: (17 June 2013) Recently, a poster on the Beowulf mailing list pointed out that not all applications need all nodes to talk to each other at full speed and low latency. This capability is often a design goal for HPC systems, and is referred to as "full bi-sectional bandwidth." For the purposes of this article, we will assume such a design goal.
Let's first consider the speed of light (SOL) in a fiber cable. After a bit of Internet searching, I found that it takes 5 ηs (nanoseconds) to travel one meter in a fiber cable (It takes light 3.3 ηs to travel one meter in a vacuum). How can we translate that into a cluster diameter? Latency is measured in seconds and the SOL is measured in meters per second. Here is one way. First we have to define some terms:
LT is the total end to end latency
Lnode is the latency of the node (getting the data on/off the wire)
Lhop is the latency of the switching chips
Nswitch is the number of switch chips.
Lcable is latency of the cable, which is a function of length
A formula may be written for the total latency as follows;
| (1) | LT = (Lnode + Lswitch*Nhop + Lcable) | |||
If we take Equation 1 and solve for Lcable, then divide the right hand side by 5 meters/ηs we get what I call the core-diameter:
| (2) | dcore = | LT - (Lnode + Lswitch*Nhop) 5 |
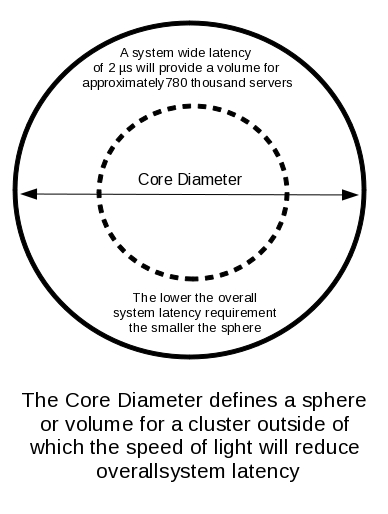
The core-diameter is the maximum diameter of a cluster in meters. It defines a volume for the cluster (sphere) beyond which the SOL will reduce system latency. Let's use some simple numbers. Suppose I need 2 μs (microseconds) latency for my applications to run well (this is LT) and my nodes contribute 1 μs and I use a total of 6 switch chips with a latency of 140 ηs (nanoseconds). I get a core diameter of 32 meters. This diameter translates to a sphere of 17 thousand cubic meters. If we take an average 1U server and assume it's volume is 0.011 cubic meters, then we could fit about 1.6 million servers in our core diameter. In practical terms, the the real amount is probably half allowing for human access, cooling, racks etc. So we are at about 780 thousand servers. If we assume 8 cores per server, then we come to a grand total of 6.2 million cores. The FLOPS rate of cores will limit the total FLOPS of the machine. If we assume a 17.5 GFLOPS per core on HPL (2.6-GHz Intel Sandy Bridge EP with Advanced Vector Extensions), then we can achieve 108 PFLOPS in the core diameter.
If we run the numbers with LT of 3 μs the number explodes to almost 600 million servers and we can see why cable distance has will not be an issue for higher latency values..
A few things about my analysis. Obviously my numbers could be refined a bit, but as a first pass they seem to work. Scaling an applications to such large numbers may be a bigger challenge than the SOL, but it does put some limits on just how big a cluster can become. Actually, it is a bit more limited than my simple analysis. There is a push-pull effect. Better scalability comes from lower latency, which decreases the diameter. Thus, in order to increase (push) the number of cores, I can use, I need to reduce the latency which due to the SOL reduces the diameter (pull) or actual number of cores I can use. Perhaps some enterprising student could come up with a model that captured this effect. I should also mention that refining the assumptions can change the actual numbers, but the push-pull effect due to the SOL is the same.
I have run out of room on the back of my envelope as I don't think this analysis can be pushed much farther without some refinements. I'll leave it as a exercise to the reader to continue the analysis. I will coin the term core-diameter, however, as it sounds cool.
This article was originally published in Linux Magazine. It has been updated and formatted for the web. If you want to read more about HPC clusters and Linux, you may wish to visit Linux Magazine. (Note: Since 2011 Linux Magazine has ceased posting new articles)

