When the best solution just won't fit the box and the budget
Note: Although this hack seems to work for point to point communications, when used with many simultaneous messages, like MPI program, there are some stalls that reduce performance. NAS benchmarks and HPL results for other similar switch-less designs will be posted soon. Good news, for small numbers of nodes performance is quite good.
Modern Ethernet technology is based on network adapters and switches. Using Ethernet without a switch only happens in rare situations where a small number (e.g. two) systems need to be directly connected together. Such a connection is often called a "cross over" connection because a special cable may be needed.
The cost of adapters and switches follow a very predictable commodity pricing trend. At first the cost of systems is quite high and decreases as the sales volumes increase. Currently Gigabit Ethernet (GigE or GbE) enjoys low cost and wide availability from multiple vendors. Ten Gigabit Ethernet (10GigE or 10GbE) is now experiencing greater acceptance and thus decreased costs. Although volumes are growing, 10GigE still commands a high per port price (Adapter/Switch) and thus can be an expensive option for many small projects.
The price of no frills two port adapters have been steadily decreasing. Currently, the Chelsio T420-SO-CR 10 Gigabit Ethernet Adapter can be found for $299 and the Mellanox ConnectX-3 10 Gigabit Ethernet Adapter can be found for $355.
There are areas where small scale 10GigE networks can be useful. The Limulus Project has produced a true desk-side HPC cluster workstation that maximizes performance, heat, noise, and power to deliver 200+ CPU-GFLOPS. The current version uses low cost GigE and a small embedded switch to connect the four single processor compute nodes. As the nodes gain more cores and become faster, the need for a faster interconnect is desirable. Placing InfiniBand or 10GigE inside such system presents a problem due to the size and the high cost of even the smallest switches.
A solution that is commodity based (i.e. low cost), requires no switch, and fits within the power/heat envelope has been elusive. The price reductions in dual port 10GigE cards, mentioned above, does offer an incentive to incorporate 10GigE in such a system. While there are several methodologies available, the lowest cost option consists of four two-port 10GigE adapters without a switch. This four node design can be pictured in Figure One below.
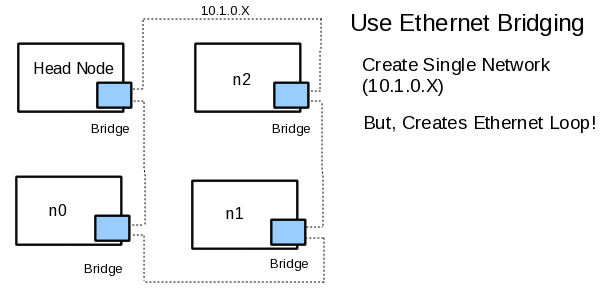
Figure One: A Unworkable Ethernet Loop
Using the Linux Ethernet Bridging capability, it is possible to turn each node into a "mini switch" forwarding any packets that are not intended for the node. This ring creates two 1-hop routes and four 0-hop routes. The problem with this design is that Ethernet does not tolerate loops. Thus, a fully connected system will not work. To solve the Ethernet loop problem, the Spanning Tree Protocol (STP) can be used on one of the nodes. Figure Two shows the result of turning STP on one for one of the nodes.
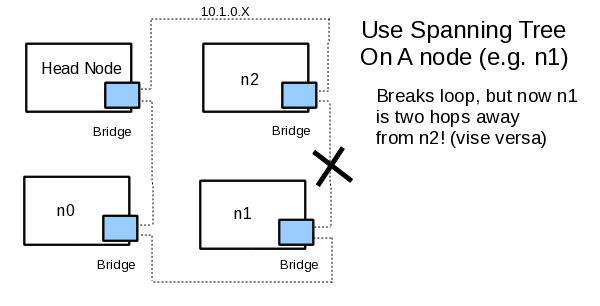
Figure Two: An Ethernet Loop with STP
While the Ethernet network will now route packets, the use of STP effectively cuts one of the links between nodes and introduces one 2-hop route, two 1-hop routes, and three 0-hop routes. The 2-hop route could cause a bottleneck and negate some of the advantages offered by adding 10GigE technology.
An interesting alternative to STP is to remove the bridging from one node and create a "bonded node" where the two 10GigE ports act like one interface. To the other nodes, the bonded node looks like an endpoint and breaks the Ethernet loop (i.e. the bonded interface does not forward packets) When bonded in mode 0, the interface can receive packets from either port and when transmitting, will alternate packets between the two ports (i.e. "round robin"). This situation is shown in Figure Three
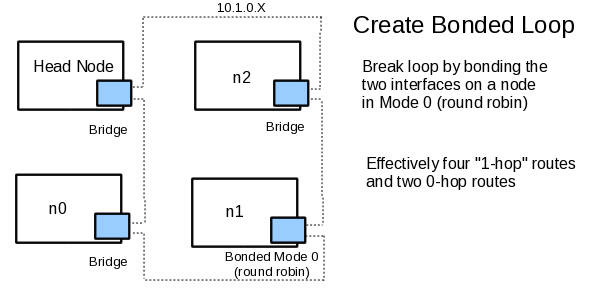
Figure Three: A Bonded Ethernet Loop
The bonded loop removes the 2-hop issue created by STP and "effectively" introduces four 1-hop routes and two 0-hop routes. The word "effectively" is important because there can still be a 2 hop path, but for only half the data, the other half ends up taking a 0-hop route due to the round robin mode. Thus, the round robin path averages out to a 1-hop path. The tests below confirm this conclusion.
Test System
The head node is Sandy Bridge, i5-2400S with 4 GB RAM and the worker nodes are single dual core E6550, with 4 GB RAM. The 10Gig Adapters are Chelsio T420-SO-CR. All adapters are connected by SFP+ cable. (Thanks to Chelsio for donating the adapters).In order to get a good test of the low level system capabilities, Open-MX was used as a transport layer. Open-MX is a freely available version of the Myricom MX library for user space communication between nodes. Both Open-MPI and MPICH2 support the Open-MX transport layer. Note, the low cost 10GigE Adapters often do not support advanced features like iWarp and Open-MX is good solution to achieve "iWarp performance" from low cost 10GigE adapters.
Also note, these tests have not been optimized. A standard 1500 Byte MTU was used for Open-MX and the node hardware is older CPU technology. Further tuning and newer hardware is expected to improve the overall performance.
Results
The omx_perf test program was used to measure the performance over all six possible routes. The best case is where a 0-hop communication occurs (headnode-n0, headnode-n2). The worst case includes any route with n1 because data will be sent from either port,thus creating an effective 1-hop path. (i.e. with n1-n0 or n1-n2 half the data is 0-hop and the other is 2-hop, n1-headnode is always two 1-hop paths, n0-n2 is a single 1-hop).Figure Four shows the standard throughput vs block size for best and worst cases. The single Byte latency is 6.5 µs for the best case and 14.2 µs for the worst case (as expected the extra hop doubles the latency.)

Figure Four: Throughput vs Blocksize
The network signature graph is shown below in Figure Five. (This style of graph was popularized by the NetPipe benchmark).
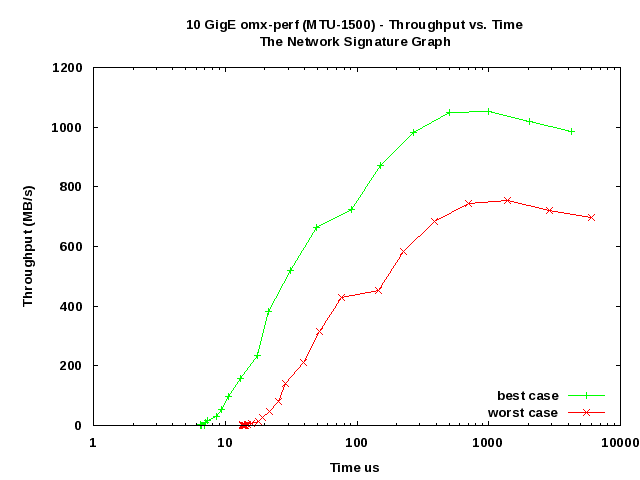
Figure Five: Network signature graph (Throughput vs Latency)
Raw data for both cases can be found below.
Conclusion
As expected, the results show impressive performance for the 0-hop cases. The effective 1-hop case has doubled the latency, however, it is still much better than the best GigE performance using Open_MX. The throughput for 0-hop is close to wire speed, while the 1-hop case is noticeably less. Again, while not optimal the 1-hop case is much better than standard GigE. In addition, without the need to buy a 10GigE switch, the network performance gain over standard GigE for approximately $1200 is hard to argue. Further high level MPI benchmarks are planed.Finally, it is possible to create a slightly higher cost star topology using a quad-port 10GigE adapter and single port adapters on the worker nodes. In this case, all communication from the hostnode to worker nodes would be 0-hops, but all worker to worker nodes would be 1 hop (i.e. three 0-hop and three 1-hop vs two 0-hop and four effective 1-hop for the ring topology described herein). This topology will be tested in the future as well.
Ultimately, how well the ring or star topology work depend on the application mix used on such a small system. At sixteen total cores, the Limulus personal cluster has enough processing power to do real work and also act as an HPC sandbox for education and development. The inclusion of high speed low latency 10-GigE is a welcome addition to this technology.
Special Thanks
The author would like to thank Chelsio for the 10-GigE adapters.Raw Data
The following are the best case "0-hop" routes (headnode-n0, headnode-n2) for omx_perf (Note: MTU is 1500 and no other tweaking).
length 0: 6.992 us 0.00 MB/s 0.00 MiB/s length 1: 6.495 us 0.15 MB/s 0.15 MiB/s length 2: 6.460 us 0.31 MB/s 0.30 MiB/s length 4: 6.575 us 0.61 MB/s 0.58 MiB/s length 8: 6.481 us 1.23 MB/s 1.18 MiB/s length 16: 6.541 us 2.45 MB/s 2.33 MiB/s length 32: 6.441 us 4.97 MB/s 4.74 MiB/s length 64: 7.045 us 9.08 MB/s 8.66 MiB/s length 128: 7.293 us 17.55 MB/s 16.74 MiB/s length 256: 8.629 us 29.67 MB/s 28.29 MiB/s length 512: 9.286 us 55.14 MB/s 52.59 MiB/s length 1024: 10.649 us 96.15 MB/s 91.70 MiB/s length 2048: 13.121 us 156.08 MB/s 148.85 MiB/s length 4096: 17.434 us 234.94 MB/s 224.05 MiB/s length 8192: 21.409 us 382.64 MB/s 364.92 MiB/s length 16384: 31.486 us 520.36 MB/s 496.25 MiB/s length 32768: 49.448 us 662.68 MB/s 631.98 MiB/s length 65536: 90.665 us 722.83 MB/s 689.35 MiB/s length 131072: 150.501 us 870.90 MB/s 830.56 MiB/s length 262144: 266.566 us 983.41 MB/s 937.85 MiB/s length 524288: 500.195 us 1048.17 MB/s 999.61 MiB/s length 1048576: 997.626 us 1051.07 MB/s 1002.38 MiB/s length 2097152: 2055.265 us 1020.38 MB/s 973.11 MiB/s length 4194304: 4249.680 us 986.97 MB/s 941.25 MiB/s
The worst case "1-hop" routes (headnode-n1, n0-n1, n0-n2, n1-n2) for omx_perf (1-hop):
length 0: 14.197 us 0.00 MB/s 0.00 MiB/s length 1: 14.280 us 0.07 MB/s 0.07 MiB/s length 2: 13.970 us 0.14 MB/s 0.14 MiB/s length 4: 13.838 us 0.29 MB/s 0.28 MiB/s length 8: 13.538 us 0.59 MB/s 0.56 MiB/s length 16: 13.689 us 1.17 MB/s 1.11 MiB/s length 32: 13.636 us 2.35 MB/s 2.24 MiB/s length 64: 14.697 us 4.35 MB/s 4.15 MiB/s length 128: 15.761 us 8.12 MB/s 7.74 MiB/s length 256: 17.786 us 14.39 MB/s 13.73 MiB/s length 512: 19.116 us 26.78 MB/s 25.54 MiB/s length 1024: 21.683 us 47.22 MB/s 45.04 MiB/s length 2048: 25.549 us 80.16 MB/s 76.44 MiB/s length 4096: 28.822 us 142.11 MB/s 135.53 MiB/s length 8192: 38.929 us 210.43 MB/s 200.68 MiB/s length 16384: 52.026 us 314.92 MB/s 300.33 MiB/s length 32768: 76.272 us 429.62 MB/s 409.72 MiB/s length 65536: 144.706 us 452.89 MB/s 431.91 MiB/s length 131072: 224.688 us 583.35 MB/s 556.33 MiB/s length 262144: 384.179 us 682.35 MB/s 650.74 MiB/s length 524288: 704.347 us 744.36 MB/s 709.88 MiB/s length 1048576: 1390.370 us 754.17 MB/s 719.23 MiB/s length 2097152: 2910.845 us 720.46 MB/s 687.09 MiB/s length 4194304: 6007.359 us 698.19 MB/s 665.85 MiB/s

