Take a moment and ask yourself the following question:
If you can have both large scale OpenMP and MPI performance in an easy to manage single system image built from commodity hardware and price points, would you prefer that a solution?
This very question was the subject a recent white paper: Redefining Scalable OpenMP and MPI Price-to-Performance with Numascale’s NumaConnect published by Numascale.
Numascale has been perfecting the NumaConnect technology and has now published several benchmarks that show both excellent shared (OpenMP) and distributed (MPI) memory performance. A Numascale cluster uses commodity hardware and the “pug-and-play” NumaConnect interconnect to deliver the ease of shared memory programming and administration at standard HPC cluster price points. One running system currently offers users over 1,700 cores with a 4.6 TByte single memory image.
Setting An OpenMP Record
In the HPC community the NAS Parallel Benchmarks are used to test the performance of parallel computers. The benchmarks are a small set of programs derived from Computational Fluid Dynamics (CFD) applications that were designed to help evaluate the performance of parallel supercomputers. Problem sizes in NAS Parallel Benchmarks are predefined and indicated as different classes (currently A through F, with F being the largest).Reference implementations of NPB are available in commonly-used programming models such as MPI and OpenMP, which make them ideal for measuring the performance of both distributed memory and SMP systems. The results below were run on a NumaConnect Shared Memory benchmark system with 1TB of memory and 256 cores (using eight servers, each equipped with two AMD Opteron 2.5 GHz 6380 CPUs, each with 16 cores and 128GB of memory). Figure One shows results for the NPB-LU benchmark (Lower-Upper Gauss-Seidel solver) scaling over a range of 16 to 121 cores using OpenMP for the Class E problem size. The results show an unprecedented number of computing cores running a NAS benchmark of this size.
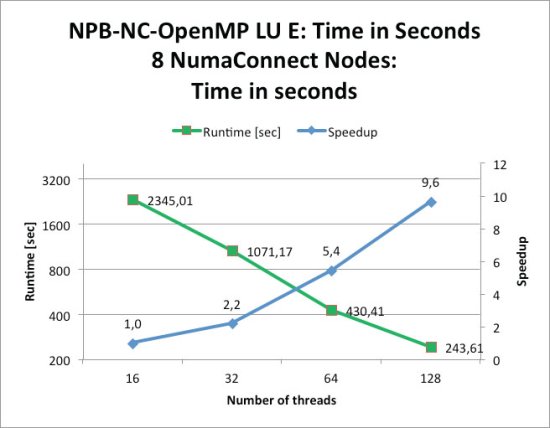
Figure One: OpenMP NAS Parallel results for NPB-LU (Class E) It should be noted that NASA has never seen OpenMP E Class results with such a high number of cores.
What about MPI Performance?
A NumaConnect cluster also excels at MPI computing within the same shared memory environment. No extra software or program modifications are needed to run large scale MPI codes. Both industry standard OpenMPI and MPICH2 work in shared memory mode. Numascale has implemented their own Numascale version of the OpenMPI BTL (Byte Transfer Layer) to optimize the communication by utilizing non-polluting store instructions.This optimization results in very efficient message passing and excellent MPI performance. As an example, consider Figure Two below for the NAS-LU (Class D) MPI benchmark. NumaConnect’s performance compared to InfiniBand may be one of the more startling results for the NAS benchmarks. Recall again that OpenMP applications cannot run on InfiniBand clusters without additional software layers and kernel modifications.
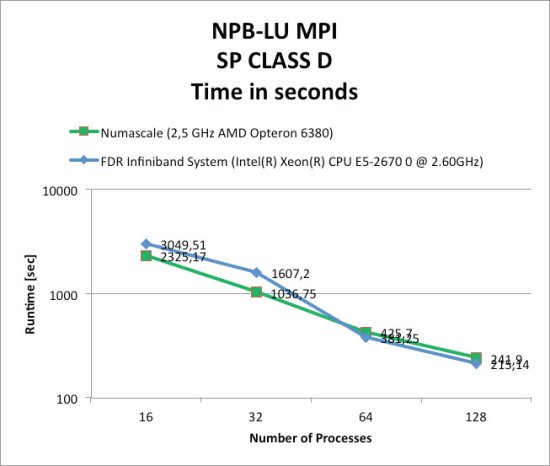
Figure Two: NPB-LU comparison of NumaConnect-MPI to FDR-MPI InfiniBand.
Additional benchmarks can be found the the white paper. There are several large scale shared memory production systems running with NumaConnect, including University of Oslo in Norway, StaOil, and Keele University.
The paper also includes an interesting cost comparison that shows a small NumaConnect cluster lands at a comparable price point to a small FDR InfiniBand cluster. There is more information in the full white paper.
Note: Douglas Eadline, author of this article is also the author of the Numascale white paper.

