Delivering big SMP performance at a cluster price

This year at SC12 Numascale, maker of low cost plug-and-play high performance shared memory systems, was showing performance numbers and some happy clients. For those that may not know, Numascale produces the NumaConnect adapter that provides plug-and-play connection of standard servers running a single un-patched OS version. Applications have fast access to the aggregate memory of all servers in the system using a hardware controlled ccNuma environment.
NumaConnect facilitates very large shared memory systems built from commodity servers at the price level of high-end clusters. This combination invites a new level of price/capability/performance that has never before been demonstrated using pure hardware. Systems built with NumaConnect run standard operating systems and all x86 applications.
NumaConnect provides an astounding memory capacity of up to 256 TBytes in a single commodity based system. "Customers with Big Data problems are excited by the ability to directly address any record anywhere in their entire data set in a microsecond or less", says Einar Rustad, co-founder and VP of Numascale. "This is orders of magnitude faster than clusters or systems based on any form of existing mass-storage devices and will enable data analysis and decision support applications to be applied in new and innovative ways", says Kåre Løchsen, Numascale founder and CEO, and adds "It is also worth also mentioning that pilot customers have been surprised by the ease of use through statements like: Using NumaConnect shared memory clusters is just like running programs on my desktop, just much more powerful!"
The technology is in test by Statoil for oil exploration applications and by the University of Oslo for general HPC datacenter use. Some of the main applications planned in Oslo are from bioscience and computational chemistry. The EU project PRACE has financed a 72-node cluster of IBM x3755’s at the University of Oslo for proving the technology. Major European HPC researchers have access to this system.
NumaConnect works with AMD Opteron based servers connecting to HyperTransport and directly addressable, shared memory can be up to 256 TBytes and provides system-wide cache coherency logic with a directory-based protocol that scales to 4096 nodes where each node can have up to three multicore processors. The cache coherency logic is implemented in an ASIC together with interconnect fabric circuitry with routing tables for multi-dimensional Torus topologies. This type of fabric is very scalable and the similar to the topology is used in the world’s largest supercomputers. Numascale also showed some data at SC12. Figure One below is an example of the stream benchmark running over 16 nodes (192 cores). Notice how NumaConnect maintains the linear scalability of a single node (yellow dashed line).
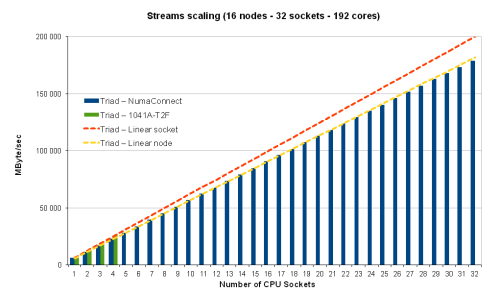
Figure One: Numascale STREAM Numbers
NumaConnect started shipping NumaConnect adaters in December 2012 for use with servers from IBM, Supermicro and AIC. Expect to hear more about this technology in 2013. For more information see the Numascale website.

